DeepSeek-V4发布加速国产AI生态发展与完善
2026年4月24日,DeepSeek-V4 Preview已正式上线并开源,成为DeepSeek在2025年R1、V3、V3.2之后的一次体系化升级,进入“低成本1M上下文长度”的阶段。此次发布的产品结构分为DeepSeek-V4-Pro与DeepSeek-V4-Flash两条线:Pro是旗舰能力版本,官方披露为1.6T总参数、49B激活参数;Flash是高速度、低成本版本,为284B总参数、13B激活参数,两者均支持100万token上下文。
1)混合注意力架构CSA+HCA:不是继续沿用标准denseattention,而是把注意力拆成两类,CSA先把KV沿序列维压缩,再做稀疏选择;HCA则用更激进的压缩,但保留denseattention。两者交替使用,目标是同时兼顾局部依赖、全局检索能力和极端长序列下的成本控制。此设计不是单点优化,而是从attention结构层面重写了长上下文的成本函数,因此能把1Mcontext真正做成系统级可运行方案。在100万token场景下,V4-Pro的单token推理FLOPs只有DeopSeek-V3.2的27%,KVcache只有10%,V4-Flash更低到10%FLOPs和7%KVcache。
2)mHC(Manifold-ConstrainedHyper-Connections):把残差连接从经验上有效变成数值上更稳定的可控结构。普通Hyper-Connections虽然能增强表达,但深层堆叠时容易数值不稳定;于是V4把残差映射矩阵约束到doublystochasticmanifold上,使其谱范数受限、残差传播变成non-expansive,从而改善深层训练稳定性。
3)把Muonoptimizer真正落到超大规模训练中:不是简单换了个优化器,而是把Muon作为大部分模块的主优化器,同时保留AdamW给embedding、norm、head等部分,再配合hybridNewton-Schulzorthogonalization去提升收敛和稳定性。
4)FP4量化训练(QAT):DeepSeek把FP4用在两个位置,一是MoEexpertweights,二是CSA里indexer的QK路径;同时还把indexscores从FP32压到BF16,使top-kselector达到2×加速,同时保留99.7%的KV召回率。同时,FP4到FP8的dequantization在其设定下可以无损地复用现有FP8训练框架,这使得低比特方案不只是理论节省显存,而是真正进入了可训练、可rollout、可部署的主干流程。
5)后训练专家独立训练+on-policydistillation统一蒸馏:不是直接把一个通用模型拿去做混合RL,而是先分别培养数学、代码、agent、instruction-following等领域专家,再通过on-policydistillation把这些能力蒸馏回一个统一模型。设计的意义在于把专才能力最强和最终交付一个通用模型两个目标拆开做,兼顾specialization和consolidation。
6)基础设施层面创新:MoE中把通信、计算、访存做成单融合kernel;更细粒度的expertwave调度来隐藏通信开销。这个MoE通信一计算融合方案不只理论可行,DeepSeek在NVIDIAGPUs和HUAWEIAscendNPUs平台上都对细粒度EP调度方案完成了验证,该方案在通用推理负载下可实现1.50-1.73倍的加速,在时延敏感型场景(如RL采样迭代、高速智能体服务)中,最高加速比可达1.96倍。
DeepSeek-V4使用超32万亿token数据对模型进行预训练,并辅以完整的后训练流程,以释放并增强模型能力。其中,DeepSeek-V4-Pro-Max(DeepSeek-V4-Pro的最高推理强度模式)在核心任务上重新定义了开源模型SOTA,性能超越其前代模型。DeepSeek-V4系列在长上下文场景下具有极高的效率,在百万token的上下文设置中,DoepSeek-V4-Pro的单token推理计算量(FLOPs)仅为DeepSeek-V3.2的27%,KV级存仅为其10%。这使得模型能够常规性支持百万token的上下文,从而让长时序任务更加可行。
演进主线:从“高效训练”到“系统重构”的清晰路径。DeepSeek 的技术演进并非简单的参数堆砌,而是一条以效率为核心的连续升级路径。
演进指标对比:V4 在参数与成本效率上实现双重突破。
三大技术信号预示 V4 变革:训练更稳、记忆更便宜、推理更轻量。V4 的发布并非孤立事件,而是2026年Q1一系列底层技术信号的集中体现,共同指向重写模型基础范式。
mHC:将信号放大倍数从 3000 倍降至 1.6 倍,奠定 V4 扩展基石。
Engram:实现存算解耦,将“记忆”从昂贵的“计算”中剥离。
FlashMLA/MODEL1:从算法创新深入至系统底层,打造独立推理路径。V4 的优化不仅停留在算法层面,更深入到了系统底层,旨在打造一个“推理更轻量”的执行环境。
核心看点:1M token 长上下文能力和强悍的 Agent 能力。DeepSeek-V4 最核心的看点是其 1M token 长上下文成为默认能力。
在 Agent 能力方面,DeepSeek 官方表示 DeepSeek-V4-Pro 在 Agentic Coding 基准上达到开源 SOTA,并且已用于 DeepSeek 内部的 agentic coding 工作。
定价方面,DeepSeek-V4 延续了 DeepSeek 一贯的“低价高性能”路线,但 Pro 与 Flash 的成本梯度更加清晰。
DeepSeek-V4 发布概况中最令产业界震动的信息,在于其底层的算力支撑。DeepSeek-V4 并不是孤立运行在某一类 GPU 上的模型,而是与国产算力适配,官方表示 DeepSeek-V4 实现了完全运行在华为昇腾(Ascend)950 PR芯片集群上。
从商业角度观察,DeepSeek-V4 最显著的产业趋势意义:
首先体现在开源前沿模型对闭源模型商业溢价的持续压缩。
第二个趋势则是国产 AI 产业链会从模型领先逐步扩散到算力、云、框架、应用、数据和工程服务的系统性机会,如果 DeepSeek 这样的高关注模型能够适配国产 AI 芯片,就会推动国内形成“模型—芯片—云—应用”的闭环。
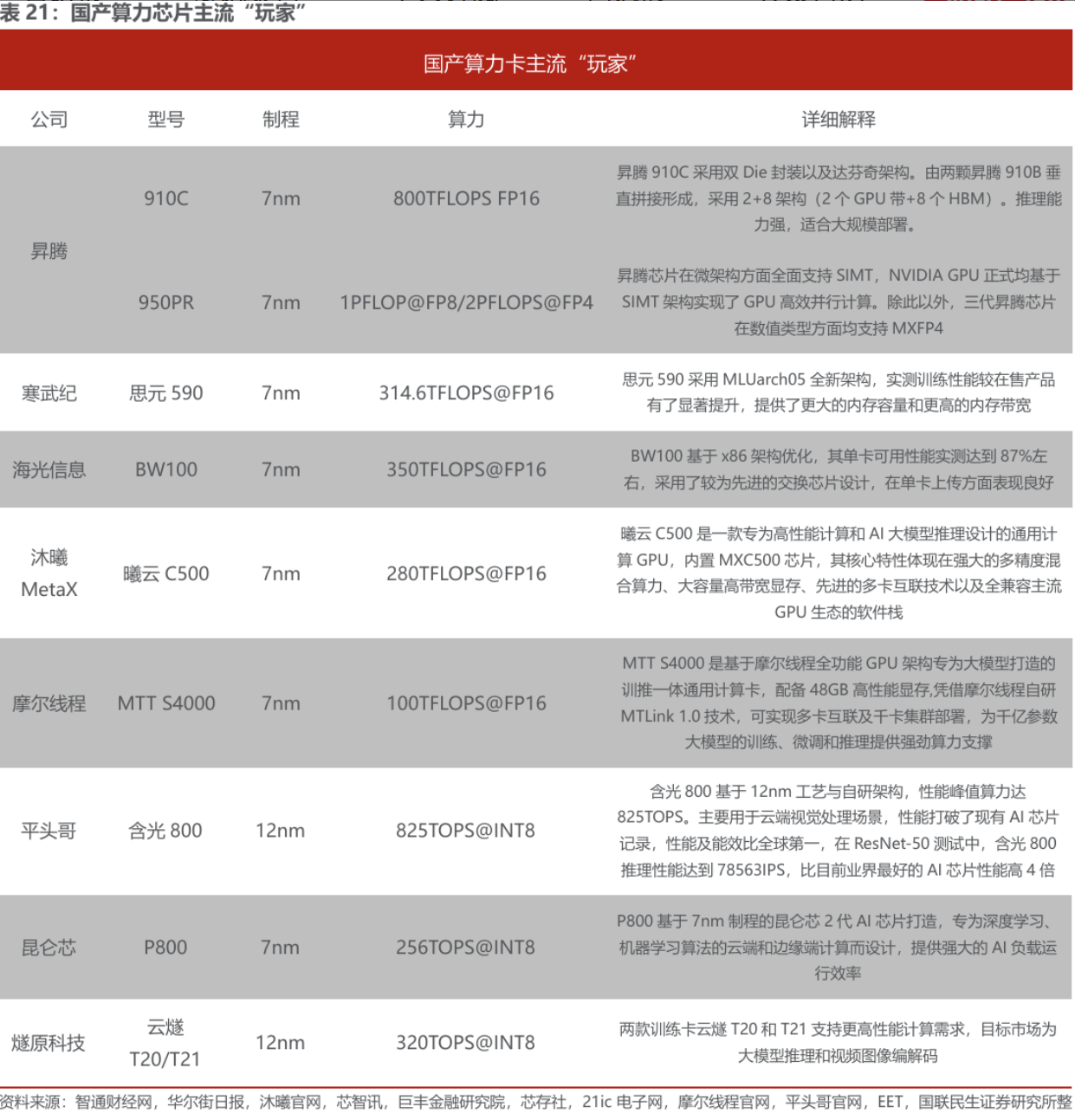
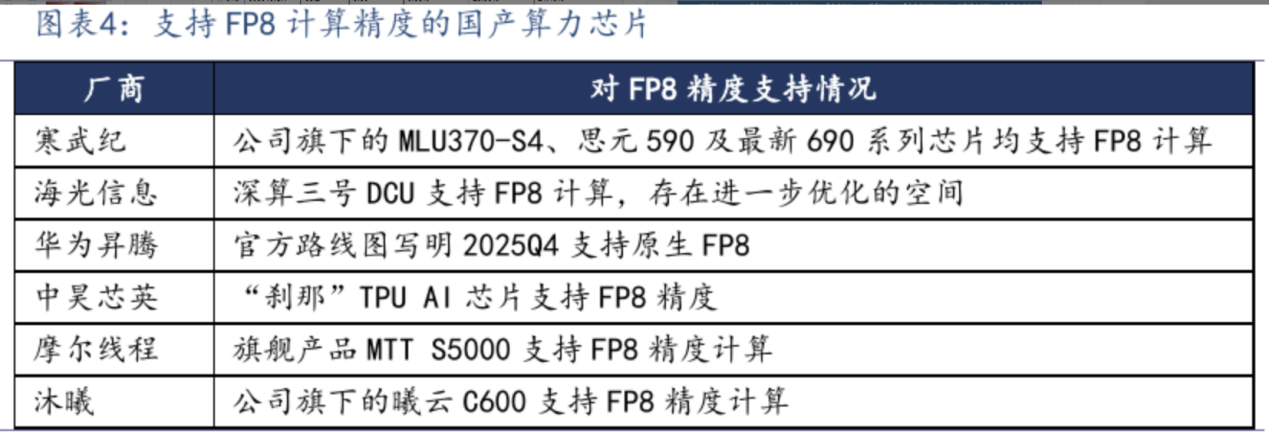
2)国产超节点龙头:浪潮信息、中科曙光、软通动力、神州数码、慧博云通、拓维信息、工业富联、彩讯股份、高新发展等;
3)云计算:金山云、网宿科技、优刻得、青云科技等。
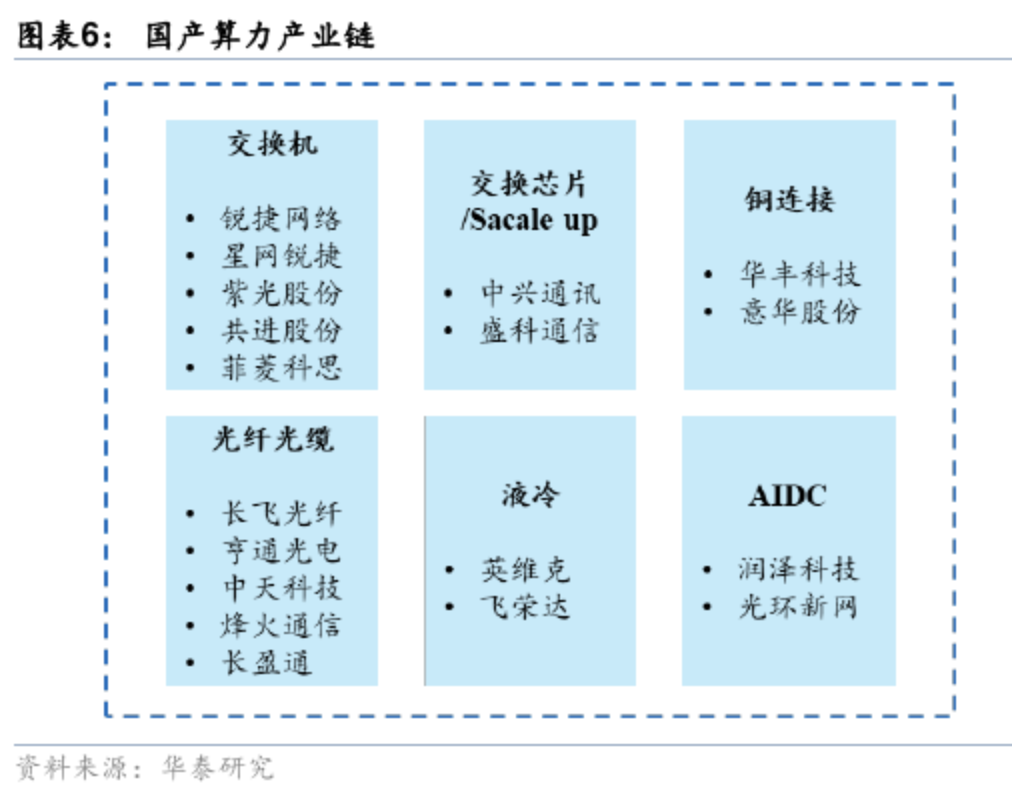
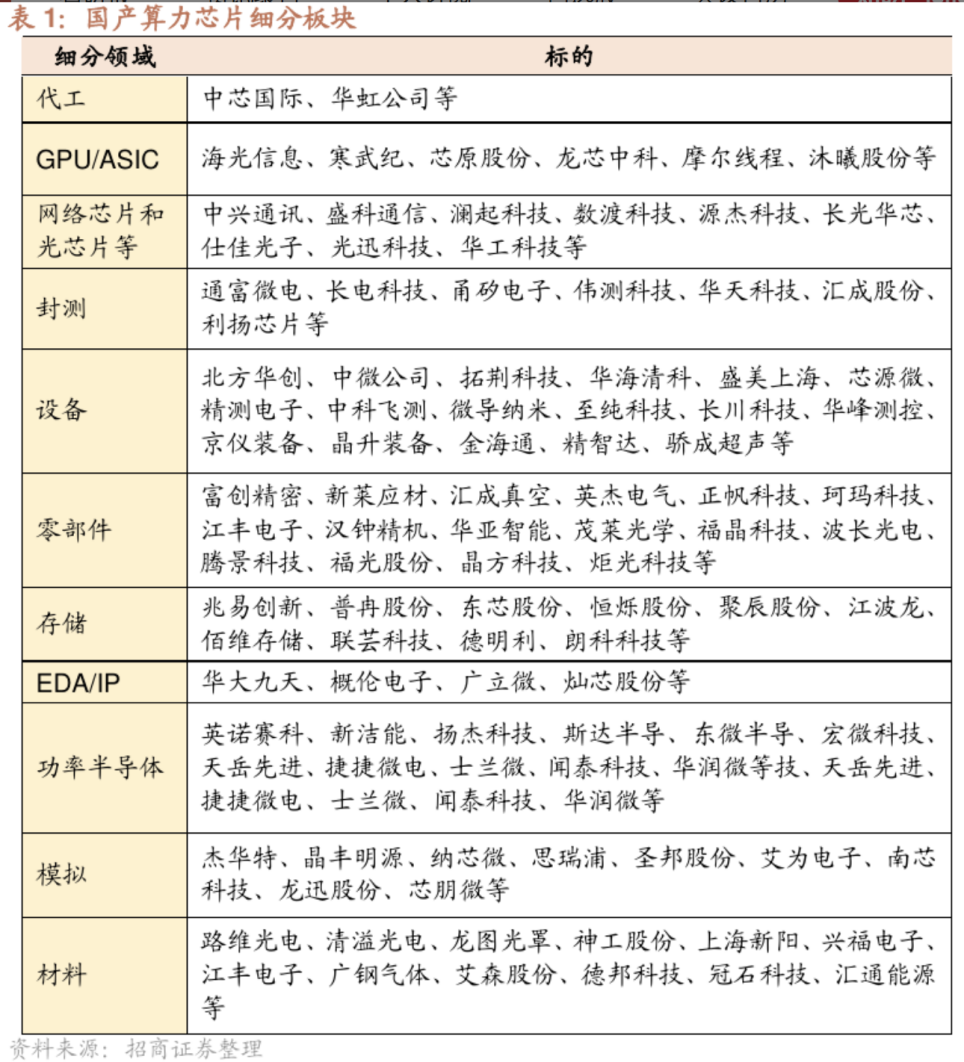
参考资料:
20260426-平安证券-DeepSeek-V4预览版本上线,国产算力快速适配
20260426-国信证券:多层面技术提升训练规模,超长上下文进入普惠时代
20260425-国联民生-深度解析DeepSeek V4:“模算协同”全国产闭环.pdf
本报告仅提供给九方金融研究所的特定客户及其他专业人士,用于市场研究、讨论和交流之目的。 未经九方金融研究所事先书面同意,不得更改或以任何方式传送、复印或派发本报告的材料、内容及其复印本予以任何第三方。如需引用、或经同意刊发,需注明出处为九方金融研究所,且不得对本报告进行有悖于原意的引用、删节和修改。 本报告由研究助理协助资料整理,由投资顾问撰写。本报告的信息均来源于市场公开消息和数据整理,本公司对报告内容(含公开信息)的准确性、完整性、及时性、有效性和适用性等不做任何陈述和保证。本公司已力求报告内容客观、公正,但报告中的观点、结论和建议仅反映撰写者在报告发出当日的设想、见解和分析方法应仅供参考。同时,本公司可发布其他与本报告所载资料不一致及结论有所不同的报告。本报告中的信息或意见不构成交易品种的买卖指令或买卖出价,投资者应自主进行投资决策,据此做出的任何投资决策与本公司或作者无关,自行承担风险,本公司和作者不因此承担任何法律责任。 投资顾问:王德慧(登记编号:A0740621120003) |
免责声明:以上内容仅供参考学习使用,不作为投资建议,此操作风险自担。投资有风险、入市需谨慎。
推荐阅读
相关股票
相关板块
相关资讯

扫码下载
九方智投app

扫码关注
九方智投公众号
头条热搜
涨幅排行榜
上海九方云智能科技有限公司 版权所有
证券投资咨询机构业务机构许可证:ZX0023
办公地址:上海市青浦区徐民东路88号1F(北塔、西北裙、东北裙、南裙)、2F(西北裙、南塔)、3F(北、西北裙、东北裙、南塔)、5F(南、北)、6F(南、北)、7F(南、北)、8F(南、北)、9F(南、北)、10F(南、北)、11F北、12F(南、北)
注册地址:上海市普陀区云岭东路89号12层1202室
 沪公网安备31011802005267号
联系电话:400-719-8899
投诉电话:021-20289058
沪公网安备31011802005267号
联系电话:400-719-8899
投诉电话:021-20289058
总经理信箱:xht_sh@newwinner.com.cn

















暂无评论
赶快抢个沙发吧