九方智投控股人工智能部门两篇论文被自然语言处理顶会 NAACL 2025 录用
北美计算语言学协会年会(The North American Chapter of the Association for Computational Linguistics,NAACL)成立于1998年,每年举办一届,是自然语言处理和计算语言学领域的重要国际学术会议。会议涵盖的内容包括但不限于自然语言理解、语言生成、机器翻译、语音识别、文本挖掘、信息检索、语言资源建设、多模态交互、社会影响和伦理问题等前沿话题。近日,NAACL 2025公布了录用论文列表,九方智投控股(9636.HK)人工智能项目部共有两篇长文被录用。NAACL在中国计算机学会CCF推荐列表中认定为B类学术会议。本次会议将于2025年4月29日-5月4日在美国新墨西哥州阿尔伯克基举行,九方智投控股也将现场参会。

(图:NAACL2025官网会议宣传海报)
这两篇论文主要是聚焦大语言模型LLM高效参数微调方向,其部分研究成果已在九方灵犀和九方智研得到实际应用。在结构化剪枝方向,我们采用了一种性能模型,结合离线元学习(offline meta-learning) 和在线增量学习(online incremental learning),探索每一层的最优秩值配置。在混合精度量化方向,我们为transformer架构中的每一层分配量化精度,并通过贝叶斯优化(Bayesian Optimization)优化精度分配策略,从而在模型准确性与内存效率之间实现平衡。这是九方智投控股九章证券领域大模型FinSphere和九方智能体FinSphere Agent核心技术部分研究成果的阶段性展示,同时也是践行九方智投控股 “科技+投研”战略的又一例证。
题目:RankAdaptor: Hierarchical Rank Allocation for Efficient Fine-Tuning Pruned LLMs via Performance Model(RankAdaptor:基于性能模型和分层秩分配方法实现高效微调剪枝大语言模型)
论文作者:周昌海,韩世杰,杨立宁,周余华,陈旭,王逸斌
通讯作者:李宏广
通讯单位:九方智投控股
合作单位:复旦大学,哥伦比亚大学,武汉大学等
录用类别:NAACL 2025 Findings长文
论文链接:https://arxiv.org/abs/2406.15734

(图:RankAdaptor技术架构图)
摘要:大型语言模型(Large Language Models, LLMs高效压缩已经成为一个越来越受关注的研究方向。然而,压缩后模型性能的恢复仍然是一个重大挑战。目前,LLM 压缩的常见实践是采用结构化剪枝(structural pruning),并结合利用 Low-Rank Adaptation (LoRA) 算法。然而,结构化剪枝对模型架构的不均匀修改,加之标准 LoRA 在线管道中对各层采用固定配置分配,导致被剪枝模型在多种下游任务中的性能表现不佳。
为了解决这一问题,我们提出了 RankAdaptor,一种分层级别的秩分配方法,能够根据各层特定的恢复需求实现剪枝后 LLM 的高效微调。我们采用了一种性能模型,结合离线元学习(offline meta-learning) 和在线增量学习(online incremental learning),探索每一层的最优秩值配置。在主流基准测试上的全面实验表明,RankAdaptor 在各种剪枝设置和 LLM 架构下始终优于最先进的方法,性能提升范围从 0.7% 到 5.5% 不等。
题目:QPruner: Probabilistic Decision Quantization for Structured Pruning in Large Language Models(QPruner:大语言模型结构化剪枝的概率决策量化方法)
论文作者:周昌海,周余华,王逸斌,韩世杰,乔巧
通讯作者:李宏广
通讯单位:九方智投控股
合作单位:复旦大学,哥伦比亚大学,浙江大学等
录用类别:NAACL 2025 Findings长文
论文链接:https://arxiv.org/pdf/2412.11629
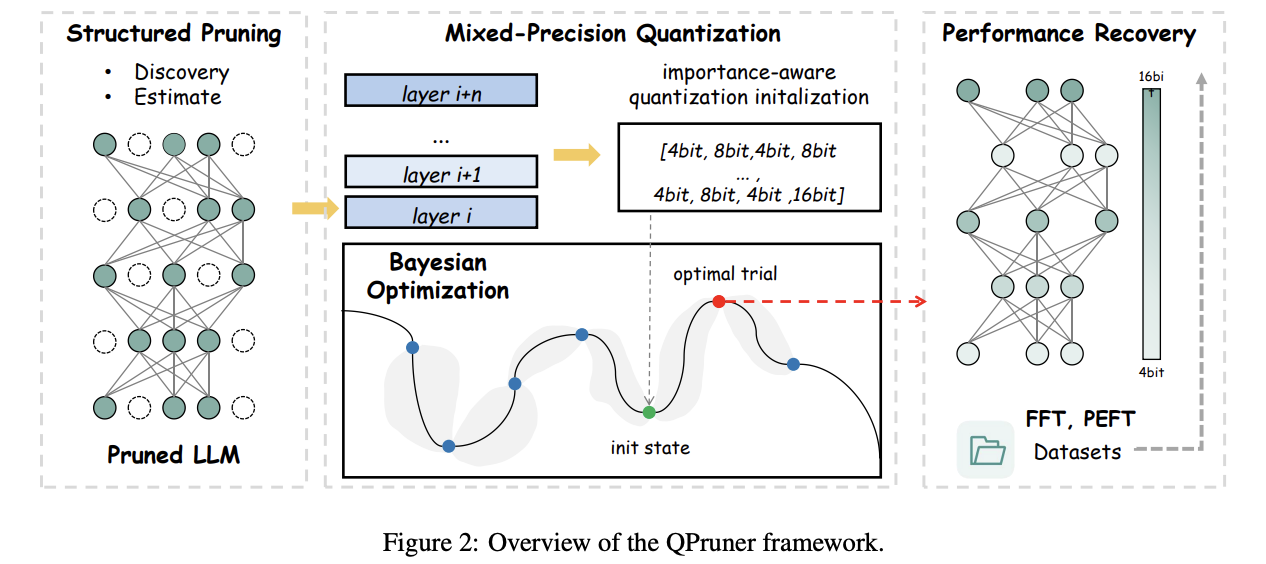
(图:QPruner技术架构图)
摘要: 大型语言模型(Large Language Models, LLMs)的兴起显著推动了各种自然语言处理(NLP)任务的发展。然而,这些模型对资源的需求带来了巨大的挑战。结构化剪枝是一种有效的模型压缩方法,可以减少模型规模,但通常会导致显著的准确性下降,从而需要通过参数更新进行适配。然而,这种微调过程需要大量内存资源,限制了其应用范围。
为了解决这些问题,我们在结构化剪枝框架中引入量化技术,在微调和推理过程中降低内存消耗。然而,剪枝和量化结合产生的误差会显著增加微调的难度,因此需要更精细的量化方案。为此,我们提出 QPruner,一个新颖的框架,首先通过结构化剪枝减少模型规模,然后结合逐层的混合精度量化策略。针对目标任务的重要性,为每一层分配量化精度,并通过贝叶斯优化(Bayesian Optimization)优化精度分配策略,从而在模型准确性与内存效率之间实现平衡。
在基准数据集上的大量实验表明,QPruner 在节省内存的同时显著优于现有方法,并能够保持甚至提升模型性能。
免责声明:以上内容仅供参考学习使用,不作为投资建议,此操作风险自担。投资有风险、入市需谨慎。
相关股票
相关板块
相关资讯

扫码下载
九方智投app

扫码关注
九方智投公众号
头条热搜
涨幅排行榜
上海九方云智能科技有限公司 版权所有
证券投资咨询机构业务机构许可证:ZX0023
办公地址:上海市青浦区徐民东路88号1F(北塔、西北裙、东北裙、南裙)、2F(西北裙、南塔)、3F(北、西北裙、东北裙、南塔)、5F(南、北)、6F(南、北)、7F(南、北)、8F(南、北)、9F(南、北)、10F(南、北)、11F北、12F(南、北)
注册地址:上海市普陀区云岭东路89号12层1202室
 沪公网安备31011802005267号
联系电话:400-719-8899
投诉电话:021-20289058 转3
沪公网安备31011802005267号
联系电话:400-719-8899
投诉电话:021-20289058 转3
总经理信箱:xht_sh@newwinner.com.cn














