



DeepSeekV3.2的发布标志着中国AI市场正式进入“第二波冲击”阶段。
12月6日,据硬AI消息,摩根大通在研报中称,这不仅仅是一次模型迭代,更是一场针对推理成本和硬件生态的结构性革命。DeepSeek通过架构创新将API价格再度下压30-70%,使得长上下文推理成本暴降6-10倍。
研报强调,更为关键的是,V3.2-Exp实现了对非CUDA生态(华为昇腾、寒武纪、海光)的“Day-0”首日支持,彻底打破了前沿模型对英伟达硬件的依赖路径。
据摩根大通分析,受益者包括云运营商阿里巴巴、腾讯、百度,以及芯片制造商中微公司、北方华创、华勤技术和浪潮信息。预计V3.2模型将在未来几个季度进一步提升生成式AI在中国的普及率。
据华尔街见闻文章,12月1日,DeepSeek发布V3.2系列两款模型并开源。V3.2主打日常应用,推理能力达GPT-5水平,首次实现思考模式与工具调用融合;V3.2-Speciale专注极致推理,在IMO、CMO、ICPC、IOI四项国际竞赛中斩获金牌。
性能与架构:效率的极致压榨与“智能体”进化
DeepSeekV3.2并非单纯堆砌参数,而是通过算法层面的创新实现了效率的质变。该模型延续了V3.1的混合专家(MoE)架构主体,但引入了DeepSeek稀疏注意力机制(DSA)。
摩根大通指出,作为9月29日首次发布的实验性V3.2-Exp模型的后续产品。V3.2模型通过持续训练引入了DeepSeek稀疏注意力机制(DSA),这是唯一的架构变动,减少了长上下文计算,同时保持了在公开基准测试中的水准。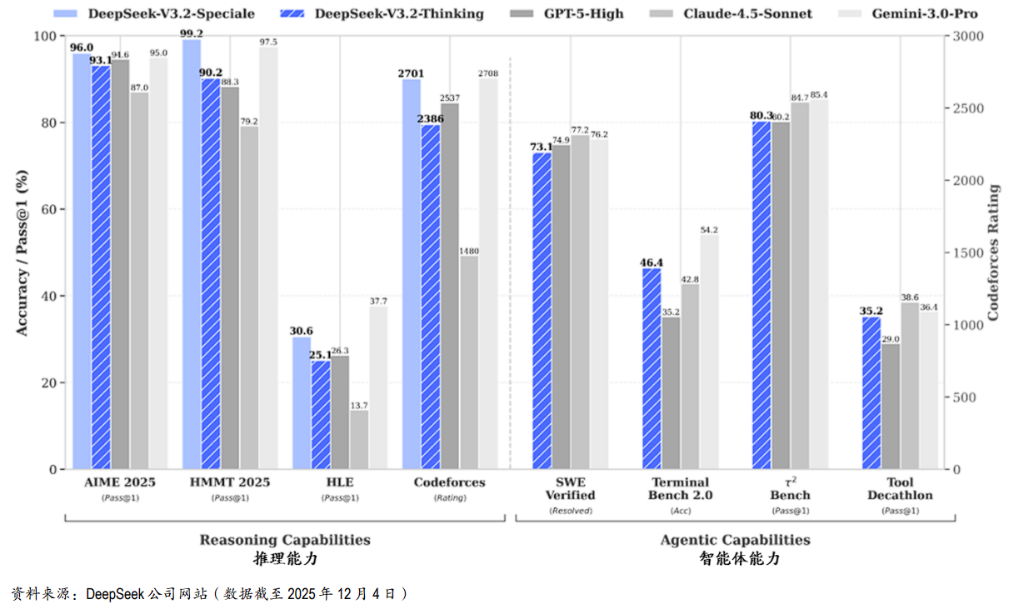
具体来看,主要包括以下四个方面:
架构突破:DSA机制通过闪电索引器选择关键键值条目,将长上下文情境下的计算复杂度从平方级(O(L2))直接降维至准线性级(O(L·k))。
性能数据:在128ktokens的长文本环境下,V3.2的推理速度较前代提升2-3倍,GPU内存占用减少30-40%,且模型性能不仅没有退步,反而保持了极高水准。
智能体定位:V3.2被明确定位为“为Agent构建的推理优先模型”。它实现了“思考+工具调用”的深度交错——模型可以在单一轨迹中结合思维链与工具调用(API、搜索、代码执行)。
高端版本:Speciale版本在奥林匹克级数学竞赛和竞争性编程中表现优异,其推理基准已媲美Gemini3.0Pro和GPT-5级系统。

定价革命:通缩的推理经济学
摩根大通指出,DeepSeekV3.2的发布再次确立了其“价格屠夫”的地位,尤其是在与美国顶级模型的对比中,展现了惊人的性价比优势。
研报认为,DSA架构带来的效率提升直接转化为了API的结构性降价。具体表现为:
具体定价:V3.2Reasoning的每百万tokens输入价格降至0.28美元,输出价格降至0.42美元。
降幅对比:相比2025年9月发布的V3.1Reasoning(输入0.42/输出1.34美元),输出成本暴跌69%,输入成本降低33%。相比2025年1月的R1模型,价格优势更加呈指数级扩大。
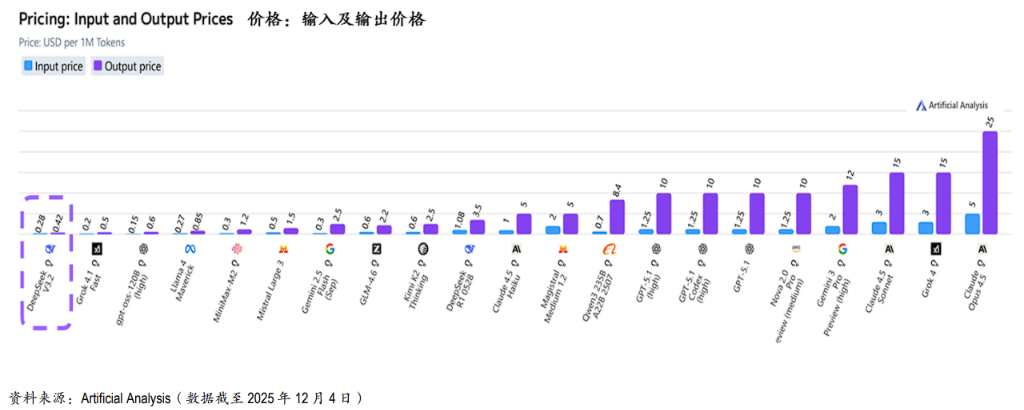
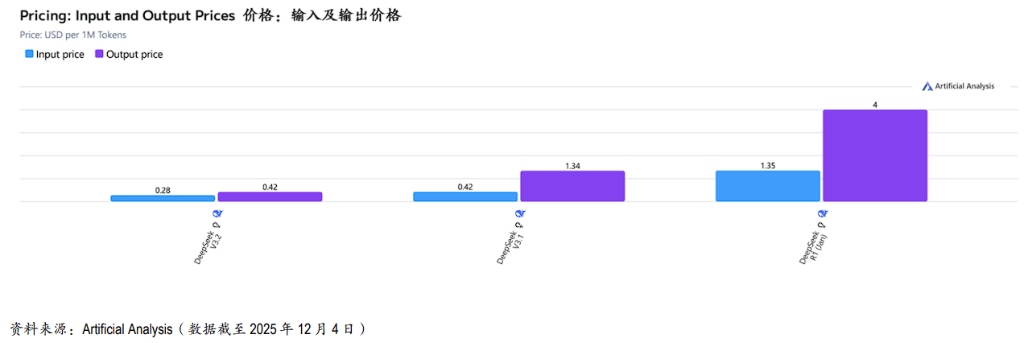
据摩根大通分析,根据第三方基准,部分长上下文推理工作负载的实际成本降低了6-10倍。这种定价策略迫使市场重新定义“前沿级”能力的成本基准,对所有竞争对手造成巨大的下行定价压力。
在ArtificialAnalysis的智能指数与价格对比中,DeepSeekV3.2处于“高智能、极低价格”的绝对优势象限。
生态重构:国产芯片的“Day-0”时刻
据研报,DeepSeekV3.2标志着中国AI模型从单纯依赖英伟达CUDA生态,转向对国产硬件的主动适配。
摩根大通称,V3.2-Exp是首批在发布首日(Day-0)即针对非CUDA生态进行优化的前沿模型,支持包括华为的CANN堆栈和Ascend(昇腾)硬件、寒武纪的vLLM-MLU以及海光的DTK。
这向市场发出了强烈的信号——GPT-5级别的开源模型可以在国产加速器上高效运行。这将由下至上降低中国AI买家的执行风险,直接带动对国产AI芯片和服务器的增量需求。








 沪公网安备31011802005267号
沪公网安备31011802005267号



