



简述:
事件:DeepSeek-V3.1正式上线,其凭借6850亿参数、128K上下文窗口及混合专家架构(MoE),在编程基准测试(中超越Claude 4 Opus,同时单任务成本低至1.01美元,仅为闭源模型的1/68。
DeepSeek V3.1大模型三大预期差:
1.agent能力大幅提升:
2.AI编程能力超预期:编程能力超过Claude 4 Opus在Aider多语言编程基准测试中取得71.6%高分,同时保持显著的成本优势。
3.使用了UE8M0 FP8 Scale的参数精度,是针对即将发布的下一代国产芯片设计。
init-width="1057" init-height="633" src="https://upload.9fzt.com/production/2025/8/22/37eff71022784e239aa5f992fbb1c205.png" name="图片 1" width="554" height="332" border="0" data-ratio="0.5992779783393501" data-w="554" style="box-sizing:border-box;width:554px;"/>
开源生态重构:DeepSeek-V3.1通过完全开源模型权重,降低企业部署门槛,加速国产AI应用落地。对比GPT-OSS-120B等海外开源模型,其在编程、长文本处理等场景更具性价比优势。
成本革命:推理成本仅约为闭源模型的1/60,推动AI应用商业化落地加速,教育、医疗、法律、金融等行业受益;
国产链崛起:模型轻量化与高效推理需求带动国产算力链(GPU、ASIC芯片、AIDC液冷)放量,国产链进展或将出现拐点。
1)国产算力:寒武纪、海光信息、龙芯中科、中兴通讯(组织优化)、中芯国际(14nm独家产能)、华为系(升腾下一代芯片,等)。
服务器:浪潮信息、中科曙光、神州数码、紫光股份、中国长城、软通动力、高新发展,拓维信息,华胜天成
AI 电源:中国长城
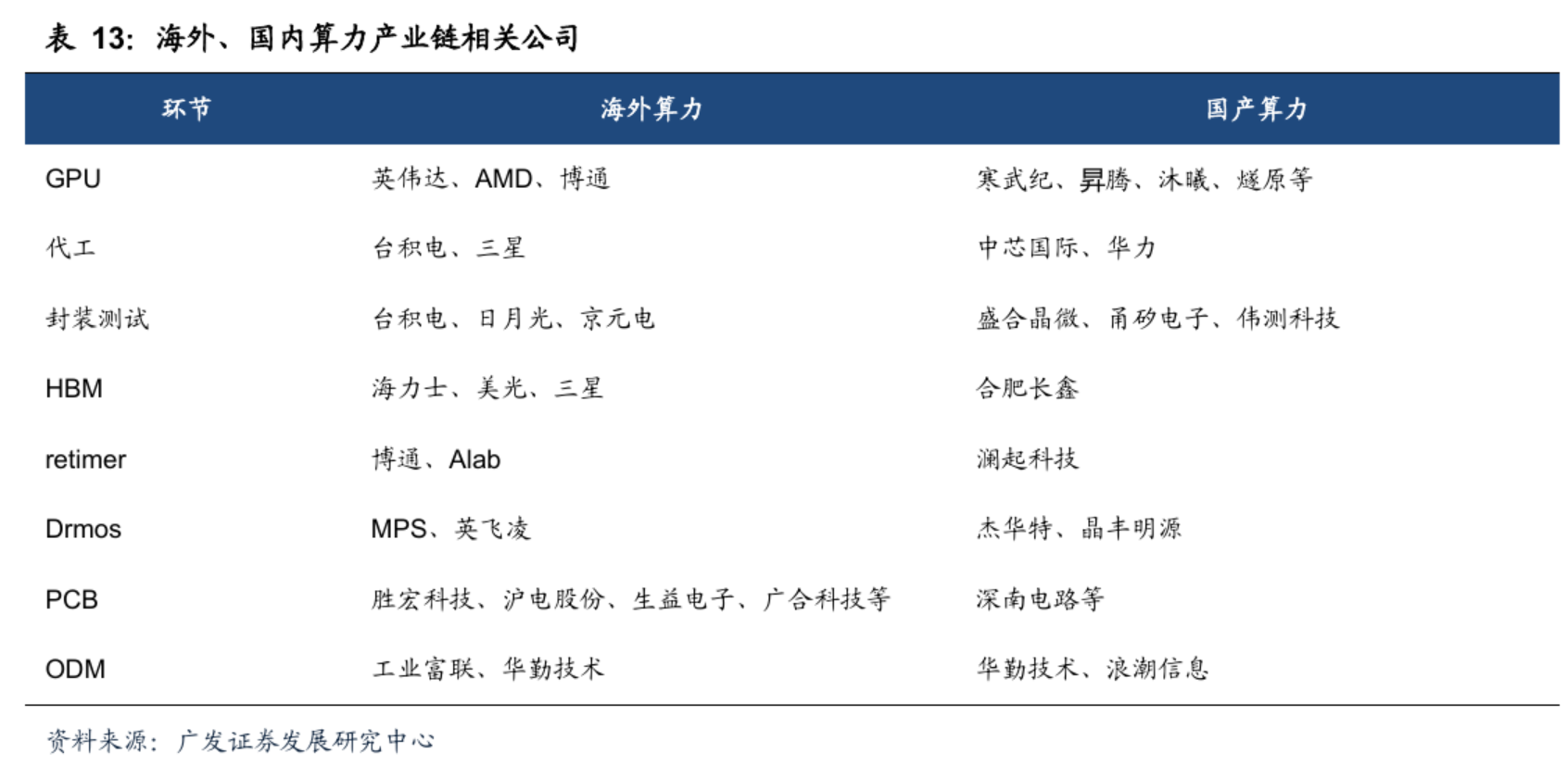
2)AI应用:金山办公、慧辰股份、能科科技、税友股份、汉得信息、新大陆、拓尔思、大智慧、同花顺、恒生电子、指南针、合合信息、卫宁健康、广联达、科大讯飞、用友网络;
3)AI算力:海光信息、寒武纪、中国长城、中科曙光、浪潮信息、紫光股份、深信服、宏景科技、智微智能;
4)国产化:中国软件、达梦数据、概伦电子、神州数码、软通动力、太极股份、龙芯中科、顶点软件;
正文:
DeepSeek V3.1版本的核心亮点是采用了全新的混合推理架构,允许模型在一个统一框架内支持“思考”与“非思考”两种模式。新版本通过训练后优化,在工具使用与编程、搜索等智能体任务上表现获得较大提升。
AI编程能力超预期
新模型在Aider多语言编程基准测试中取得71.6%高分,超越包括Claude 4 Opus在内的多个知名模型,同时保持显著的成本优势。这一性能突破已在开发者社区引发广泛关注,模型在Hugging Face平台的热度迅速攀升。
DeepSeek同步升级了API接口,将上下文窗口扩展至128K,并新增了对Anthropic API格式的支持以简化迁移。更重要的是,公司宣布将于2025年9月6日起执行新的API定价方案并取消夜间优惠,这被视为其在服务能力扩容后,加速商业化进程的关键一步。
1.混合推理架构:一个模型同时支持思考模式与非思考模式;
2.更高的思考效率:相比 DeepSeek-R1-0528,DeepSeek-V3.1-Think 能在更短时间内给出答案;V3.1和V3.1 Think相比V3和R1,达到同样效果需要的token数明显减少。注意这是提效而不是通缩,因为后续可以通过加算力获得额外性能。
3.更强的Agent能力:通过后训练,增强了工具使用能力,Agent任务提升显著。通过Post-Training优化,新模型在工具使用与智能体任务中的表现有较大提升。在效率方面,新的思考模式(V3.1-Think)经过思维链压缩训练,相比上一代模型(R1-0528),在任务表现基本持平的情况下,token消耗量可减少20%至50%。
4.预训练。 V3.1 Base在V3基础上重新做了外扩训练,增加训练了 840B tokens(vs V3训练了14.8T,大概比例是5.7%)。虽然增加的token不多,但是依然证明预训练和智能性是正比的,预训练还未结束。
5.DeepSeek-V3.1通过使用UE8M0 FP8 Scale的参数精度和MOE架构,推动国产算力替代与智能算力需求增长;与传统的FP16(半精度浮点数)和FP32(单精度浮点数)相比,FP8通过减少数据位宽来实现更高的计算效率和更低的内存占用。其低成本推理(闭源1/68)和行业实测高准确率加速AI在金融、医疗等场景落地;开源生态(MIT协议)降低Agent开发门槛,催化国产Agent在垂直领域商业化。我们看好国产算力与agent投资机会。
FP8是原版V3采用的精度,FP8的两种主流编码是E4M3和E5M2(英伟达、Arm、Intel定的),UE8M0代表在E4M3和E5M2的一种缩放,但是本质还是8位代表一个数。
UE8M0 FP8概念:FP代表浮点数(小数),8代表数据用8bit(8位0、1)表示。计算机里的小数都是用科学计数法表示的,只不过与通常的科学计数法不同,不是10的次方,而是2的次方,例如3.14可以表示为1.57*2^1,0.618可以表示为1.236*2^(-1)。
U:Unsigned,无符号,与有符号(Signed)相对应,也就是数字不带正负号,这种数据格式无法表示负数,但是可以用同样的数据长度表示更多正数。
E:Exponent,指数,科学计数法的“次方”。
M:Mantissa,尾数,科学计数法的“头”或“有效数字”。
UE8M0:无符号(只能取0或正数),用8位数字表达指数,用0位数字表达尾数(此时尾数默认为1) ,也就 是说这种数字格式只能表示2的n次方,从2的0次方到2的255次方。
UE8M0与常规FP8的区别:常规FP8通常是“(S1)E5M2”或者“(S1)E4M3”,对数据的表示范围有所不同。
2)FP8精度:E4M3、E5M2、UE8M0等多种格式都代表什么?
E4M3=1位符号+4位指数+3 位尾数。动态范围小,精度较高,就像一本“小本子”,能记细节,但容量有限。
E5M2:1位符号+5 位指数+2 位尾数。动态范围大,精度差,就像一张“粗略地图”,范围很广,但细节模糊。
UE8M0:8位指数,没有符号和尾数,只能表示 2^n 倍数,非常适合存缩放因子、就像相机的调焦光圈,让画面(E4M3/E5M2)放大或者缩小,来适应相框(训练/推理)的需要。
计算/存储数值用E4M3/E5M2省算力和显存,缩放用UE8M0提高稳定性和生态兼容性。
3)UE8M0首先出自NVIDIA PTX指令集,主要用来作为 MXFP8 训练推理中的缩放因子。DS-V3/R1在对FP8 稳定训练方面做出了突出贡献,并通过 DeepGEMM 这样的开源库把这种实现公开出来。DeepGEMM 的README就直接写了“SM100 需要 packed UE8M0 缩放因子”,并提供了相应kernel,帮助整个生态在工程上落地。
NVIDIA 提供了标准(UE8M0 格式),而DeepSeek贡献了工程实现与大规模实践(DeepGEMM代码、FP8 稳定训练方案)
UE8M0 FP8,对算力影响:
1)FP8:相比FP16可以节约一半算力/显存容量/通信带宽,相比FP32能节约3/4。数据长度的缩短,有利于提升计算速度,并且可以用更少的算力卡、更小的集群装下模型。沿着该思路,使用FP6、FP4更能节约算力、显存、带宽。
2)UE8M0:可以把计算中占据大多数的乘法转化为更简单的加法。由于科学计数法的“头”全是1,所以数据只能是2的n次方。由于神经网络中,主要的运算是矩阵乘法,而2的n次方乘法,比通常的乘法简单很多,可以简化为加法,例如2^m * 2^n = 2^(m+n)。
3)加法相比乘法,快很多、简单很多。通常,加法器电路的面积比乘法器小很多,一次乘法运算消耗的时间是加法的数倍。
国产芯片要支持FP8,需要同时满足
①芯片硬件在算子层面原生支持E4M3/E5M2
②支持UE8M0 等FP8缩放标准
对原本只支持BF16/FP16精度的老芯片,可以通过 FP8 存储 + 转换 BF16/FP16 计算,节省显存/带宽。对未来新发布的原生支持FP8的国产芯片,即可享受满血版的算力/显存/带宽约2x的效率提升。
UE8M0格式的乘法,比其他FP8快数倍,且明显节约芯片面积。推出更灵活的数据格式UE8M0 FP8,是Deepseek通过更进一步的工程优化(类似采用FP8数据训练),针对国产AI芯片算力不足的问题做的优化 (动态的去减少尾数可以使得更多的计算采用整数乘法器进行操作,可以较大程度的释放算力,在国产芯片设计端,未来在有限的制程下也可以塞入更多的整形计算单元来堆砌更多算力)。
核心1:低精度训练可以提高吞吐量,降低内存与带宽消耗,强调了FP8等低精度训练的重要性。
核心2:采用UE8M0 FP8可以帮助平衡FP8训练的动态范围和精度,在国产卡支持FP8精度的初期阶段,通过软件层的优化、带来国产卡FP8精度的调优与使用效率提升。
UE8M0 FP8,对模型影响:
在现有算力条件下,采用新数据格式可以大幅提升训练推理效率,加快模型迭代。
同样的显存容量下,可以增大等效KV Cache容量,增加上下文长度,对于模型的记忆能力、复杂项目分析能力大有助益。
同样的网络带宽下,可以增加网络效率、集群效率,降低模型公司成本,改善用户体验。
国产算力支撑国产模型,本次DeepSeek V3.1有望助推国产算力竞争力提升,看好国产算力与国产模型合力支撑下的中国AI产业。
对存储需求的影响:不同的FP8格式实际上在存储单元的占用均为8 bit,实际上对内存单元以及内存带宽的需求并没有任何优化或者变化,因此部分公众号中解读的所谓利空HBM,降低存储需求的表述是明显错误的。只要为FP8的格式,那么读写都是8bit的存储单元占用。
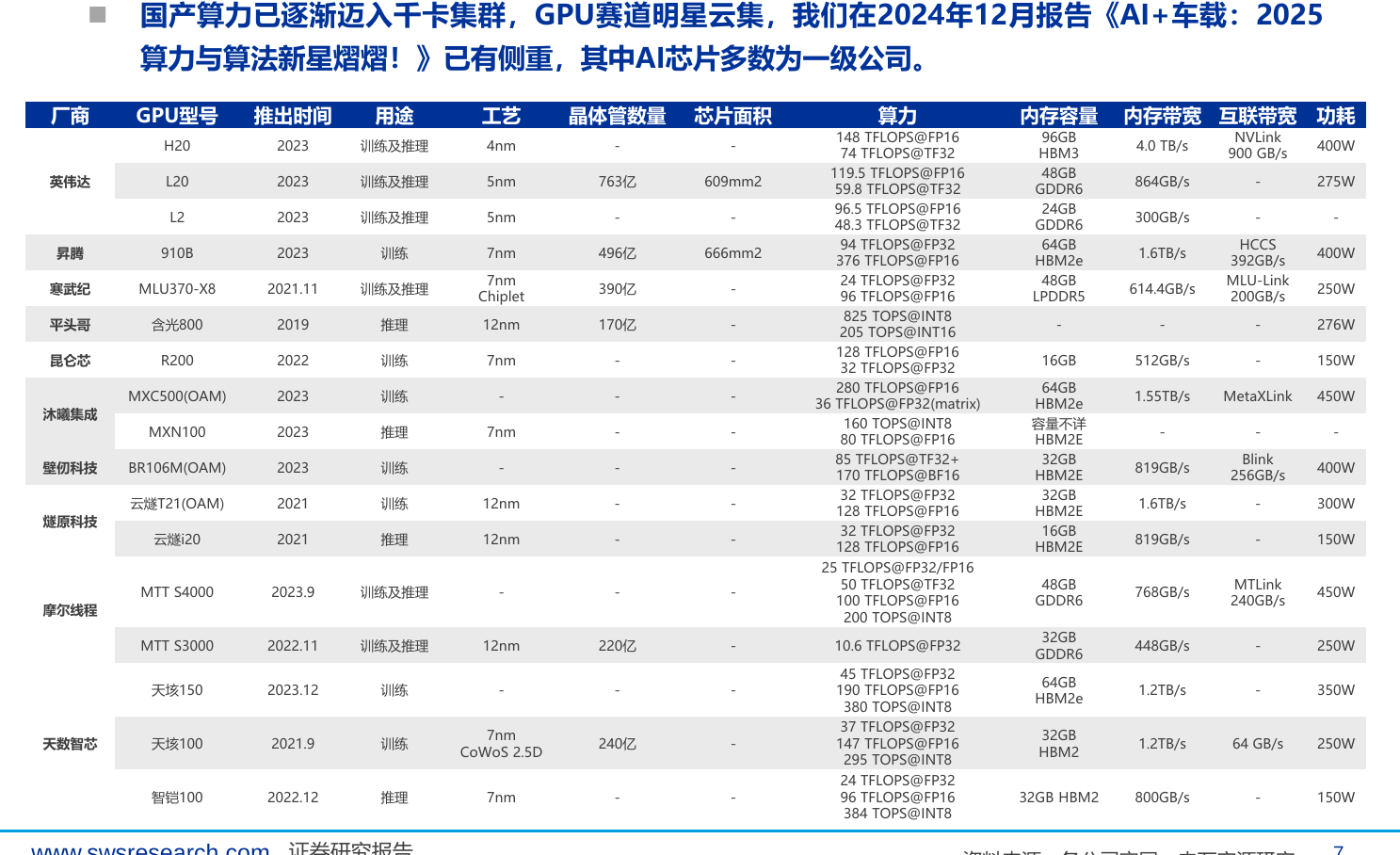
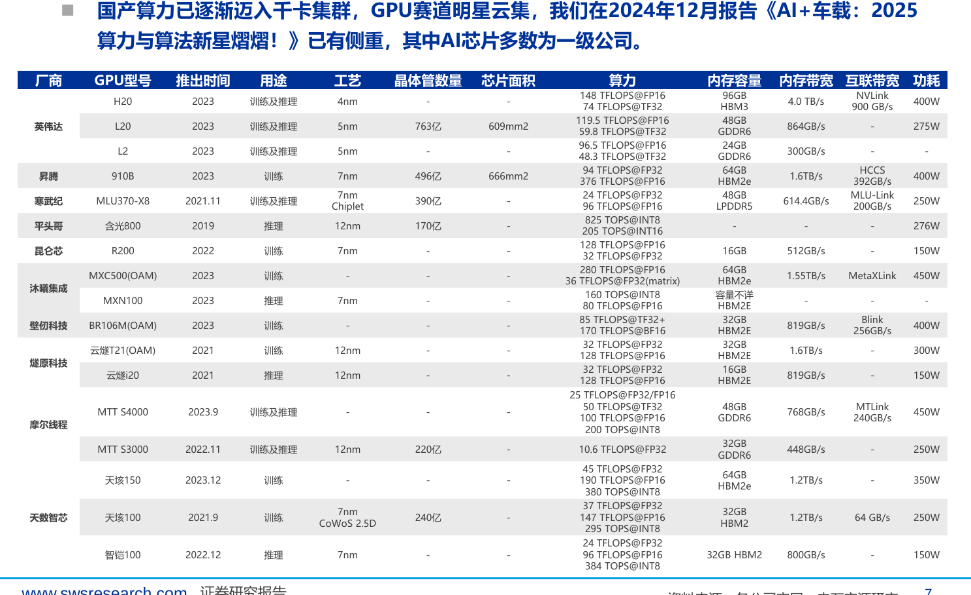
国产芯片推理部署:华为升腾910C不支持FP8,下一代芯片将支持;寒武纪受限于FP16,需转换精度。
华为下一代芯片(可能命名为910x)将支持FP8精度,预计第四季度送测厂商。当前910B库存积压,主要用于推理而非训练。寒武纪690、摩尔线程S5000等国产芯片已支持FP8,但华为生态软件适配更优。国产GPU架构自主可控问题:计算公司公告称“力争解决”,实际未完全自主(采用Imagination IP)。
8月12日,华为推出AI推理创新技术——推理记忆数据管理器UCM,通过多级缓存显著优化AI推理体验与性价比。UCM是一款以KVCache和记忆管理为中心的推理加速套件,提供全场景系列化推理加速方案,通过推理框架、算力、存储三层协同,优化Tokens在各业务环节中流转的效率,以实现AI推理的更优体验、更低成本。其三大组件包括对接不同引擎与算力的推理引擎插件(Connector)、支持多级KVCache管理及加速算法的功能库(Accelerator)、高性能KVCache存取适配器(Adapter),并通过开放统一的南北向接口,可适配多类型推理引擎框架、算力及存储系统。经大量测试验证,UCM可将首Token时延最高降低90%,系统吞吐最大提升22倍,实现10倍级上下文窗口扩展。
华为计划在今年9月正式开源UCM,届时将在魔擎社区首发,后续逐步贡献给业界主流推理引擎社区,希望通过开放开源的方式,让业界共享这一成果,共同推动AI推理生态的繁荣发展。李国杰强调,用AI处理更高级别的问题,信息量和数据输出会更大,UCM则能够大幅优化成本。今天发布的UCM,是华为第一次提供如此完整的全流程、全场景且可演进的系统性方案。从单点算力模组转向系统级优化,是一个大的变化和趋势。业界有很多开源方案有类似的方向,有的是做了其中某一层或某一些组件,但是并未看到可商用的端到端完整方案。
2025年8月国产芯片成果丰硕。华为Pura80系列明确搭载麒麟9020,架构升级,封装技术先进,体现供应链突破与自信,其芯片覆盖多终端,未来性能将再跃升。海光信息新一代C86处理器性能提升,生态完善,业绩增长,计划整合构建全栈能力。澜起科技推出的C6P系列CPU优势显著,竞争力强。国产芯片迭代迅猛,自主创新动能强劲,未来在全球赛道将占更核心位置。
1)国产算力:寒武纪、海光信息、龙芯中科、中兴通讯(组织优化)、中芯国际(14nm独家产能)、华为系(升腾下一代芯片,等)。
服务器:浪潮信息、中科曙光、神州数码、紫光股份、中国长城、软通动力、高新发展,拓维信息,华胜天成
算力租赁:宏景科技、智微智能、协创数据
AI 电源:中国长城
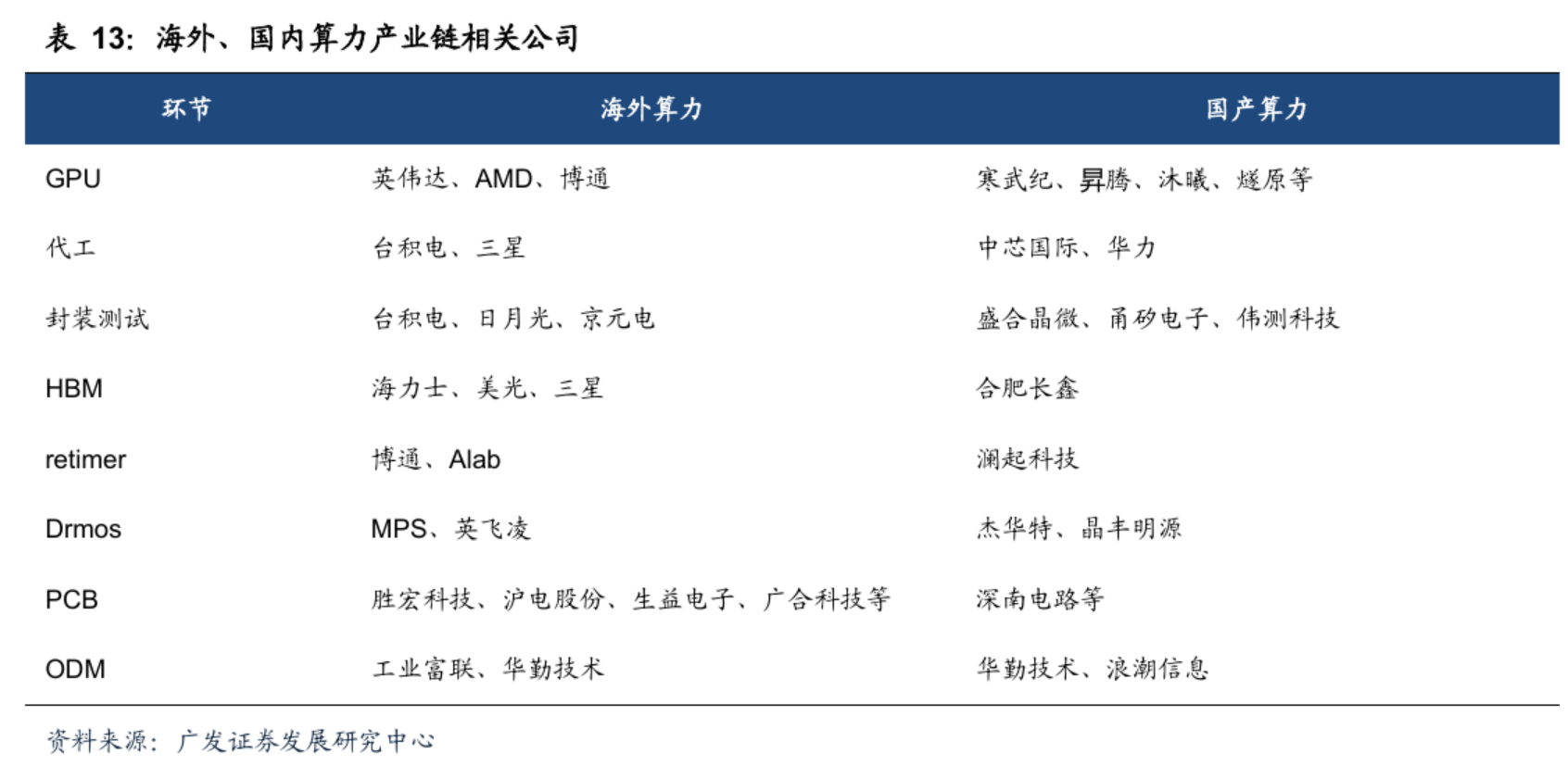
2)AI应用:金山办公、慧辰股份、能科科技、税友股份、汉得信息、新大陆、拓尔思、大智慧、同花顺、恒生电子、指南针、合合信息、卫宁健康、广联达、科大讯飞、用友网络;
3)AI算力:海光信息、寒武纪、中国长城、中科曙光、浪潮信息、紫光股份、深信服、宏景科技、智微智能;
4)国产化:中国软件、达梦数据、概伦电子、神州数码、软通动力、太极股份、龙芯中科、顶点软件;
5)eCall:慧翰股份、鸿泉物联、千方科技。
参考资料:
20250817-华西证券-再现麒麟芯,国产算力崛起
20250817-兴业证券-计算机:大模型及应用加速升级,持续看好国产算力链
本报告仅提供给九方金融研究所的特定客户及其他专业人士,用于市场研究、讨论和交流之目的。 未经九方金融研究所事先书面同意,不得更改或以任何方式传送、复印或派发本报告的材料、内容及其复印本予以任何第三方。如需引用、或经同意刊发,需注明出处为九方金融研究所,且不得对本报告进行有悖于原意的引用、删节和修改。 本报告由研究助理协助资料整理,由投资顾问撰写。本报告的信息均来源于市场公开消息和数据整理,本公司对报告内容(含公开信息)的准确性、完整性、及时性、有效性和适用性等不做任何陈述和保证。本公司已力求报告内容客观、公正,但报告中的观点、结论和建议仅反映撰写者在报告发出当日的设想、见解和分析方法应仅供参考。同时,本公司可发布其他与本报告所载资料不一致及结论有所不同的报告。本报告中的信息或意见不构成交易品种的买卖指令或买卖出价,投资者应自主进行投资决策,据此做出的任何投资决策与本公司或作者无关,自行承担风险,本公司和作者不因此承担任何法律责任。 投资顾问:王德慧(登记编号:A0740621120003) |









 沪公网安备31011802005267号
沪公网安备31011802005267号



