



对金融机构的IT负责人而言,核心系统的国产化改造,大概是这几年分量最重、也最有考验的一道必答题。政策方向是明确的,技术路线是可选的,但所有人心里都清楚——动核心数据库,就是动全行的根基。停机窗口是卡死的,业务连续性是刚性的,出一点问题就是全行级的生产事故。
近期,中亦科技与某农信银行携手完成全量系统全栈国产化改造迁移工作,成功投产上线。100TB+全量核心业务数据、数百套业务系统,在4小时的停机窗口内完成全量割接。
新系统上线后,读写吞吐量提升2-3倍,联机报表分析时效提升11倍,核心业务SQL整体性能提升约40%——不止是完成了国产化替换,更实现了架构能力的全面升级。
这场硬仗的难度,从来不止技术
这个项目之所以有参考价值,正是因为它直面了核心系统迁移里的几个难题。
第一,十几年的集中式架构,换分布式能不能扛住核心账务?
该行原有核心系统基于IBM小型机+Oracle数据库+EMC高端存储的集中式IOE架构,已经稳定运行了十余年。这套架构在过去支撑了业务的平稳运转,但随着业务规模扩大,短板已经越来越明显:集中式数据库锁机制复杂度高,多实例下冲突剧增,性能越往上顶越吃力;节点数量受限,单点故障风险突出,核心节点或存储一旦出问题,就是全系统瘫痪。
但从集中式切到分布式,不是换个软件这么简单。十几年积累的海量PL/SQL存储过程、触发器、业务包,沉淀了全行核心账务的全部规则。业务逻辑容不得错,用户体验容不得降,这个风险,谁都不敢轻易冒。
第二,分布式架构上线前能不能全摸清?
很多项目POC阶段指标亮眼,一到真实生产就掉链子,核心原因就在于此。
集中式架构下的一条普通更新,到分布式环境里,分片策略选错了,就可能变成跨多节点的分布式事务,高峰期延迟直接翻倍。测试数据是均匀分布的,真实业务数据有冷热、有倾斜,实验室里跑通的方案,放到真实交易场景里未必成立。更不用说跨行内系统、对接外部监管的复杂调用链路,任何一处兼容性问题,都可能导致上线后连锁故障。等上线了再发现问题,早已错过了调整的窗口。
第三,百TB数据对几小时窗口,能不能赶得完?
100TB+的全量核心数据,要在短短几小时内完成迁移、校验、验证全流程,本身就是一道极难的算术题。
传统串行迁移的方式根本赶不上,可并行迁移又要面对数据一致性的考验。停机超时就意味着第二天网点无法正常营业,影响的是全行的经营秩序,没有延期的余地。
第四,谁来为结果兜底?
技术方案可以写得尽善尽美,应急预案可以做得面面俱到,但真到割接当晚,所有的压力最终都会落在决策者身上。
切换失败能不能回退?回退会不会造成数据丢失?业务停摆的责任谁来承担?这才是很多人迟迟不敢拍板的根本原因——技术问题总有解法,但责任的重量,没人能轻易接下。
把所有风险前置,让确定性贯穿全流程
面对这些难题,我们的核心思路始终如一——要在投产之前,把所有能预见的风险全部化解。我们陪着客户,从架构选型、SQL适配到迁移策略、容灾设计,把每一个环节反复打磨,把所有不确定性,一点点变成100%的确定性。
选型是所有工作的起点。经过多轮深度评估与压测验证,客户最终选定TiDB分布式数据库作为核心系统的技术底座,搭配国产ARM服务器完成全栈自主化改造。我们的工作,就是把产品的原生能力,和客户的实际业务场景做深度适配,让产品优势真正落地到核心账务场景里,而不是停留在纸面参数上。确定了技术底座之后,考验才刚开始。
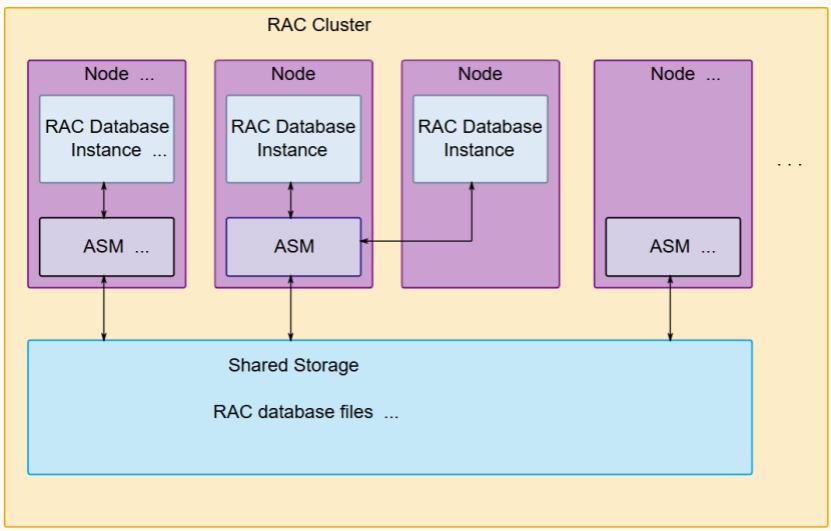
(原系统改造前的数据库架构)
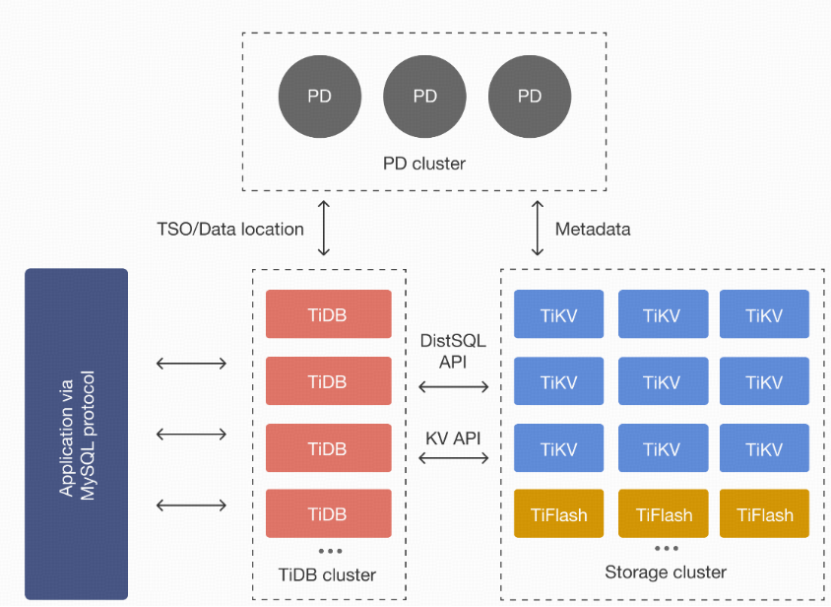
(全栈国产化改造后的数据库架构)
一、分组并行迁移策略,破解“体量大+窗口短”的矛盾
针对100TB+数据量、“单表超大”的典型农信场景,我们没有采用传统的串行迁移方式,而是设计了一套精细化的分组并行迁移策略。
核心思路是:对每一张表的业务属性、数据量、关联依赖进行逐一分析,按业务特征拆分为可独立并行的任务单元,差异化设定迁移优先级与并行度,最大化利用停机窗口的每一分钟。配合自研的异构数据库迁移工具,单节点迁移效率可达150GB/小时,在提速的同时通过全量校验严格保障数据一致性,最终整体全量数据迁移周期控制在一周内完成。
更关键的是,我们全程陪着客户完成了6次全流程投产演练。每一次演练都完全复刻正式割接的标准与流程,记录每一步的实际耗时,排查每一个隐藏的卡点,优化每一处可压缩的时间冗余。到第6次演练结束时,整个切换流程的每一步操作都已精确到分钟,正式投产不过是再走一遍已经验证过6次的成熟路径。
二、全量SQL深度调优:不只是“能用”,更要“更好用”
这是整个项目中技术含量最高、也最见功底的环节。我们基于分布式数据库的特性,对全量业务SQL进行了逐条回放与深度优化。优化工作完全贴合分布式架构的特性,从多个维度精准发力。
-
调整SQL执行计划路径,用TiDB的分布式算子下推能力替代原集中式的单线程扫描,充分释放多节点算力; -
将性能较差的IN子查询改写为exists,减少结果集物化带来的内存开销; -
对嵌套关联子查询进行解耦重构,避免逐行执行导致的性能衰减; -
针对大数据量排序、分组场景,适配分布式数据库的内存参数与算子执行策略,规避内存溢出风险; -
根据优化器特性,在不同业务场景下精准匹配HashJoin与IndexJoin策略,最大化关联查询效率; -
推动计算算子下推到存储节点执行,大幅减少网络传输与数据重分布的开销。
同时,我们充分利用TiFlash列式存储引擎的能力,对报表分析类业务做了专项适配,让复杂联机查询直接在交易库上实时运行。最终核心业务SQL整体性能提升约40%,读写吞吐量提升2-3倍,联机报表分析时效更是提升了11倍。
三、精细化切换管控,稳稳守住4小时红线
几百套系统的启停有严格的依赖关系,差一个环节、错一步顺序,都可能打乱全盘节奏。
我们协助客户搭建了“分工到人、责任到岗、节点到分”的精细化执行机制,每套系统的停机时机、校验节点、启动顺序,全部明确到人、闭环到岗。从数据校验、迁移执行到业务验证、上线切换,每个环节的衔接都经过反复推演。
正式割接当晚,各小组按预设流程环环相扣、无缝衔接,全程没有意外、没有卡顿,稳稳地在4小时内完成了数百套系统的全量切换。
四、四层容灾架构设计,给长期稳定运行扎实兜底
迁移的终点从来不是系统成功上线,而是未来多年的平稳运行。对于金融核心系统而言,高可用与容灾能力,是比迁移本身更重要的长期保障。
我们协助客户搭建了一套超大规模分布式集群方案,整套系统部署186套数据库集群,每套均采用标准三节点部署架构,从底层就具备原生高可用能力。在此之上,构建了完整的四级容灾防护体系,层层递进覆盖所有故障场景:
-
集群层高可用:分布式数据库原生的多副本共识机制,单台或少量节点故障时,集群可自动仲裁、秒级切换,业务完全无感知; -
同城灾备:通过CDC实时数据同步,搭建同城灾备集群,应对机房级断电、火灾等极端故障; -
异地灾备:部署异地灾备节点,应对地域级灾害风险,保障核心数据不丢失; -
全量数据备份:定期全量+增量备份,作为数据安全的最后一道防线。
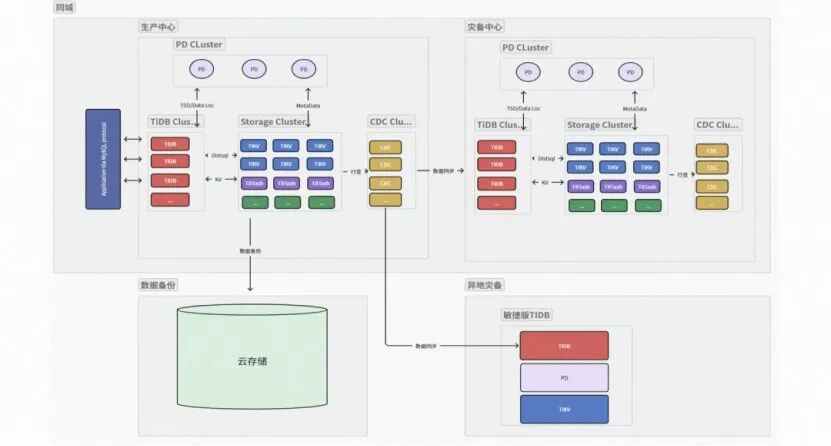
这套体系从节点到集群、从机房到地域,把所有可能的故障场景都覆盖在内。对客户而言,不只是迁移成功了,更是未来很多年的核心系统运行,都有了扎实的安全底座。
国产化是主动升级的契机
项目最终的圆满落地,除了性能的显著提升,更在成本与长期运维层面带来了实实在在的价值:
-
硬件成本下降:用国产ARM通用服务器替代传统高端小型机与集中式存储,采购成本显著降低;HTAP混合负载能力省掉了独立分析库的硬件投入,算力利用率大幅提升; -
开发适配成本可控:数据库支持自动分片与自适应负载均衡,对业务层透明,不用为分布式架构额外投入大量改造人力; -
运维效率显著提升:面对客户对日常巡检“频次低、覆盖不全、标准难统一”的困扰,中亦团队为客户构建了从脚本开发、定时调度到结果归档的自动化巡检闭环方案。它让系统健康状态的评估从“不定期人工抽查”升级为“每日自动覆盖”,为数百套集群的日常运维建立了一道可靠的基线保障防线。
而在我们看来,这个案例更大的价值在于:它又一次的证明了核心系统全栈国产化,只要有科学的选型、扎实的适配、成熟的实施方法论、完善的兜底保障,一次性平稳落地完全可以实现。
中亦科技深耕IT基础架构领域二十余年,服务过2900余家行业头部客户,见过几乎所有核心系统迁移可能遇到的问题,也陪着众多机构走完了国产化的关键一步。
无论机构选择哪一种技术路线、哪一款数据库产品,我们始终和企业一致。从企业的业务现状与实际需求出发,制定最适配的方案,把风险提前化解,把流程反复打磨,最终稳稳地把项目落地。
核心系统国产化这道必答题,我们陪企业一起,交一份经得起检验的答卷!
(中亦科技 动态宝)








 沪公网安备31011802005267号
沪公网安备31011802005267号



